November 2021 update
Categories:
Published by the PipeCD dev team every month, this update will provide you with news and updates about the project! Please click here if you want to see the last status update.
What’s changed
Last month, PipeCD team has introduced 4 releases (v0.20.0, v0.20.1, v0.20.2, v0.21.0). Those releases bring many updates to help PipeCD becomes more stable as well as introduce some interesting features. In this blog post, we will recap those new features. For all other changes, please check out each release note to see.
Lambda Deployment
Before v0.20.0, PipeCD only supports deploying an AWS Lambda function by using container image as the input. It means that to run a Lambda function, you have to prepare its container image by building the source code and storing its image in a container registry. That preparation is normally considered as a responsibility of a CI system. That way is straightforward and has been highly recommended recently in the Cloud Native development process.
But to provide more flexibility to the developers, especially those are still not able to apply container technology into their development process. Starting from v0.20.0 PipeCD introduces two new ways to deploy an AWS Lambda function: deploying directly from source code stored in Git, deploying a Zip packing code stored in AWS S3.
# Deploy Lambda function directly from source code stored in a Git repository.
apiVersion: pipecd.dev/v1beta1
kind: LambdaFunction
spec:
name: SimpleFunction
source:
git: git@github.com:username/lambda-function-code.git
ref: v1.0.0
path: hello-world# Deploy Lambda function by a Zip packing source code stored in S3.
apiVersion: pipecd.dev/v1beta1
kind: LambdaFunction
spec:
name: SimpleFunction
s3Bucket: pipecd-sample-lambda
s3Key: pipecd-sample-src
s3ObjectVersion: 1pTK9_v0Kd7I8Sk4n6abzCL# Deploy Lambda function by using a container image.
apiVersion: pipecd.dev/v1beta1
kind: LambdaFunction
spec:
name: SimpleFunction
image: ecr.ap-northeast-1.amazonaws.com/lambda-test:v0.0.1Check out its documentation for more details.
Automated Deployment Analysis (ADA)
ADA is a good way to automate the process of evaluating the impact of a deployment during its lifetime to help building a robust release process. Any application can be configured to analyze its deployments based on its metrics data, log messages, or results from directly emitting requests to the application.
Until now, PipeCD has been providing a way to allow the developer to configure a list of query and threshold to analyze metrics data of a running deployment. Any query that returns a result exceeding the given threshold will cause the deployment to be failed, and a rollback stage will be executed if needed. Although this way is relatively straightforward, there is a challenge you can see here; it isn’t easy to find an appropriate threshold value to use since software is constantly changing time over time that making those values could be changed dynamically. Therefore, some new analysis strategies PREVIOUS, CANARY_BASELINE, CANARY_PRIMARY have been introduced since v0.20.0. They allow analyzing without requiring any threshold values.
Sum up, you can choose one of the following four strategies which fits your use case:
PREVIOUS: A method to compare the time series of metrics data between the running and the last successful deploymentCANARY_BASELINE: A method to compare the time series of metrics data between the Canary and Baseline variantsCANARY_PRIMARY: A method to compare the time series of metrics data between the Canary and Primary variantsTHRESHOLD: A method to check the given queries againts the given thresholds
# ADA by comparing the time series of metrics data between the running and the last successful deployment.
- name: ANALYSIS
with:
duration: 30m
metrics:
- strategy: PREVIOUS
provider: my-prometheus
deviation: HIGH
interval: 5m
query: sum (rate(http_requests_total{status=~"5.*"}[5m])) / sum (rate(http_requests_total[5m]))# ADA by comparing the time series of metrics data between the Canary and Baseline variants.
- name: ANALYSIS
with:
duration: 30m
metrics:
- strategy: CANARY_BASELINE
provider: my-prometheus
deviation: HIGH
interval: 5m
query: sum (rate(http_requests_total{job="foo-{{ .Variant.Name }}", status=~"5.*"}[5m])) / sum (rate(http_requests_total{job="foo-{{ .Variant.Name }}"}[5m]))# ADA by checking the given queries againts the given thresholds.
- name: ANALYSIS
with:
duration: 30m
metrics:
- strategy: THRESHOLD
provider: my-prometheus
interval: 5m
expected:
max: 0.01
query: sum (rate(http_requests_total{status=~"5.*"}[5m])) / sum (rate(http_requests_total[5m]))Check out its documentation for more details.
Notification
Any PipeCD event (deployment triggered, planned, analysis completed…) can be configured to send to external services like Slack or a Webhook service. While forwarding those events to a chat service helps developers have a quick and convenient way to know the deployment’s current status, forwarding to a Webhook service may be useful for triggering other related tasks.
Until now, only Slack has been supported. From v0.21.0 you can configure your Pipeds to send its events to external services via Webhook. See here to know how to configure.
Besides that, events sent to Slack can be configured to mention one or multiple Slack users. It would be helpful to prevent developers from missing important events.
apiVersion: pipecd.dev/v1beta1
kind: KubernetesApp
spec:
pipeline:
stages:
- name: K8S_CANARY_ROLLOUT
- name: WAIT_APPROVAL
- name: K8S_PRIMARY_ROLLOUT
- name: K8S_CANARY_CLEAN
notification:
mentions:
- event: DEPLOYMENT_WAIT_APPROVAL
slack:
- slack-user-id-1
- slack-user-id-2
- event: "*" # Specifying "*" means mentioning the given users for all events.
slack:
- slack-user-id-3
Piped Operation
As you know, PipeCD is designed with control-plane and agent model (see component architecture diagram). Piped is a single binary agent you run in your cluster, your local network to handle the deployment tasks related to that cluster. It can be run as a Pod inside a Kubernetes cluster, as a process in a virtual machine, or even on your local machine. Piped is stateless so that it can be restarted without worrying about data loss. That helps the product team reduce the cost of maintaining their Pipeds. You can see those installation guides to know how to install Piped on each environment.
From v0.20.0, managing Piped has become even easier than ever. With Remote-Upgrade feature, you can restart the currently running Piped with another version from the web console. And with Remote-Config feature, you can enforce your Piped to use the latest config data just by updating its config file stored in a remote location such as a Git repository.
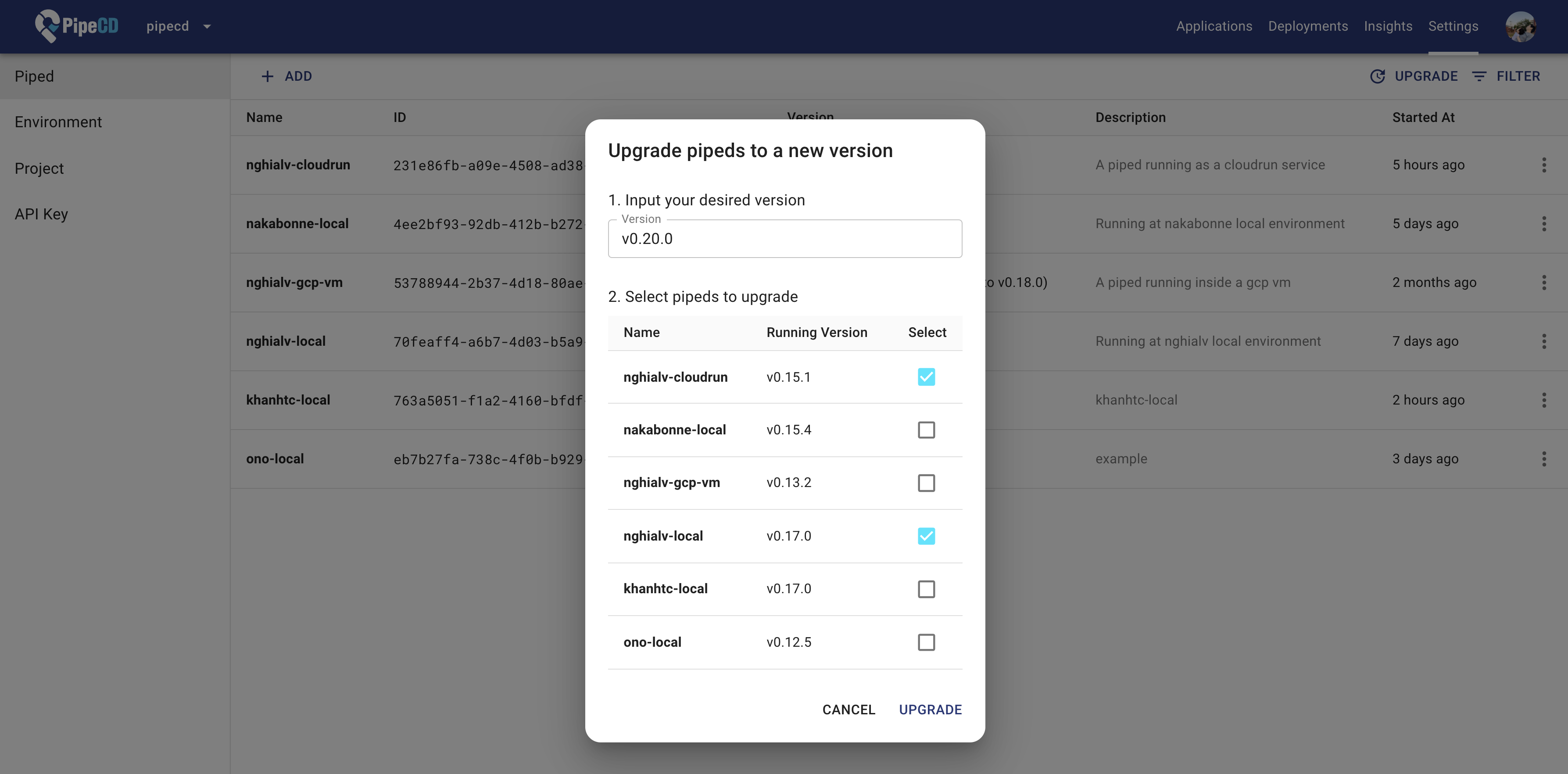
Select a list of Pipeds to upgrade from Settings page
Talks
Two members from PipeCD team did talk about PipeCD at some local events in Japan.
-
2021/10/08 - Introducing PipeCD as a unified CD system for both infrastructure and application
Cloud Native Developers JP, by @nghialv (Youtube video in Japanese)
-
2021/10/29 - How to deploy AWS application with GitOps style by PipeCD
What are next
The team continues actively working on improving PipeCD product. Besides fixing the reported issues, enhancing the existing features, here are some new features the team is currently working on:
- Deployment Chain - Allow rolling out to multiple clusters gradually or promoting across environments
- Resource Tagging - A better way to group and filter PipeCD resources such as applications, deployments
If you have any features want to request or find out a problem, please let us know by creating issues to the pipe-cd/pipecd repository.
Follow us on Twitter to keep track of all the latest news: https://twitter.com/pipecd_dev